OPTIMIZE TABLE
Optimizing a table in Databend involves compacting or purging historical data to save storage space and enhance query performance.
Why Optimize?
Databend Data Storage: Snapshot, Segment, and Block
Snapshot, segment, and block are the concepts Databend uses for data storage. Databend uses them to construct a hierarchical structure for storing table data.
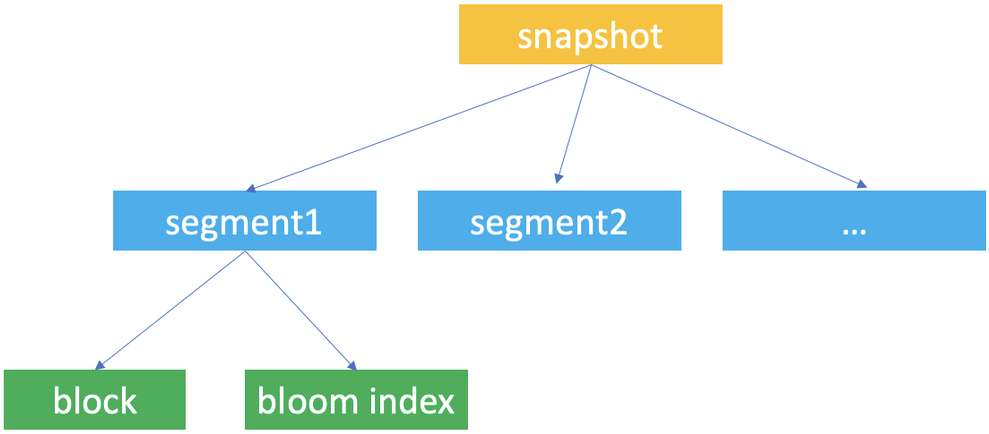
Databend automatically creates table snapshots upon data updates. A snapshot represents a version of the table's segment metadata.
When working with Databend, you're most likely to access a snapshot with the snapshot ID when you retrieve and query a previous version of the table's data with the AT clause.
A snapshot is a JSON file that does not save the table's data but indicate the segments the snapshot links to. If you run FUSE_SNAPSHOT against a table, you can find the saved snapshots for the table.
A segment is a JSON file that organizes the storage blocks (at least 1, at most 1,000) where the data is stored. If you run FUSE_SEGMENT against a snapshot with the snapshot ID, you can find which segments are referenced by the snapshot.
Databends saves actual table data in parquet files and considers each parquet file as a block. If you run FUSE_BLOCK against a snapshot with the snapshot ID, you can find which blocks are referenced by the snapshot.
Databend creates a unique ID for each database and table for storing the snapshot, segment, and block files and saves them to your object storage in the path <bucket_name>/<tenant_id>/<db_id>/<table_id>/. Each snapshot, segment, and block file is named with a UUID (32-character lowercase hexadecimal string).
| File | Format | Filename | Storage Folder |
|---|---|---|---|
| Snapshot | JSON | <32bitUUID>_<version>.json | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_ss/ |
| Segment | JSON | <32bitUUID>_<version>.json | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_sg/ |
| Block | parquet | <32bitUUID>_<version>.parquet | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_b/ |
Table Optimizations
In Databend, it's advisable to aim for an ideal block size of either 100MB (uncompressed) or 1,000,000 rows, with each segment consisting of 1,000 blocks. To maximize table optimization, it's crucial to gain a clear understanding of when and how to apply various optimization techniques, such as Segment Compaction, Block Compaction, and Purging.
When using the COPY INTO or REPLACE INTO command to write data into a table that includes a cluster key, Databend will automatically initiate a re-clustering process, as well as a segment and block compact process.
Segment & block compactions support distributed execution in cluster environments. You can enable them by setting ENABLE_DISTRIBUTED_COMPACT to 1. This helps enhance data query performance and scalability in cluster environments.
SET enable_distributed_compact = 1;
Segment Compaction
Compact segments when a table has too many small segments (less than 100 blocks per segment).
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'The table needs segment compact now',
'The table does not need segment compact now'
) AS advice
FROM
fuse_snapshot('your-database', 'your-table')
LIMIT 1;
Syntax
OPTIMIZE TABLE [database.]table_name COMPACT SEGMENT [LIMIT <segment_count>]
Compacts the table data by merging small segments into larger ones.
- The option LIMIT sets the maximum number of segments to be compacted. In this case, Databend will select and compact the latest segments.
Example
-- Check whether need segment compact
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'The table needs segment compact now',
'The table does not need segment compact now'
) AS advice
FROM
fuse_snapshot('hits', 'hits');
+-------------+---------------+-------------------------------------+
| block_count | segment_count | advice |
+-------------+---------------+-------------------------------------+
| 751 | 32 | The table needs segment compact now |
+-------------+---------------+-------------------------------------+
-- Compact segment
OPTIMIZE TABLE hits COMPACT SEGMENT;
-- Check again
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'The table needs segment compact now',
'The table does not need segment compact now'
) AS advice
FROM
fuse_snapshot('hits', 'hits')
LIMIT 1;
+-------------+---------------+---------------------------------------------+
| block_count | segment_count | advice |
+-------------+---------------+---------------------------------------------+
| 751 | 1 | The table does not need segment compact now |
+-------------+---------------+---------------------------------------------+
Block Compaction
Compact blocks when a table has a large number of small blocks or when the table has a high percentage of inserted, deleted, or updated rows.
You can check it with if the uncompressed size of each block is close to the perfect size of 100MB.
If the size is less than 50MB, we suggest doing block compaction, as it indicates too many small blocks:
SELECT
block_count,
humanize_size(bytes_uncompressed / block_count) AS per_block_uncompressed_size,
IF(
bytes_uncompressed / block_count / 1024 / 1024 < 50,
'The table needs block compact now',
'The table does not need block compact now'
) AS advice
FROM
fuse_snapshot('your-database', 'your-table')
LIMIT 1;
We recommend performing segment compaction first, followed by block compaction.
Syntax
OPTIMIZE TABLE [database.]table_name COMPACT [LIMIT <segment_count>]
Compacts the table data by merging small blocks and segments into larger ones.
This command creates a new snapshot (along with compacted segments and blocks) of the most recent table data without affecting the existing storage files, so the storage space won't be released until you purge the historical data.
Depending on the size of the given table, it may take quite a while to complete the execution.
The option LIMIT sets the maximum number of segments to be compacted. In this case, Databend will select and compact the latest segments.
Databend will automatically re-cluster a clustered table after the compacting process.
Example
OPTIMIZE TABLE my_database.my_table COMPACT LIMIT 50;
Purging
Purging permanently removes historical data, including unused snapshots, segments, and blocks, except for the snapshots within the retention period (including the segments and blocks referenced by this snapshot), which will be retained. This can save storage space but may affect the Time Travel feature. Consider purging when:
The storage cost is a major concern, and you don't require historical data for Time Travel or other purposes.
You've compacted your table and want to remove older, unused data.
Historical data within the default retention period of 12 hours will not be removed. To adjust the retention period according to your needs, you can use the retention_period setting. In the Example section below, you can see how the retention period is initially set to 0, enabling you to insert data into the table and immediately remove historical data.
Syntax
OPTIMIZE TABLE <table_name> PURGE [BEFORE (SNAPSHOT => '<SNAPSHOT_ID>')
| (TIMESTAMP => '<TIMESTAMP>'::TIMESTAMP)] [LIMIT <snapshot_count>]
[BEFORE (SNAPSHOT => '<SNAPSHOT_ID>') | (TIMESTAMP => '<TIMESTAMP>'::TIMESTAMP)]Purges the historical data that was generated before the specified snapshot or timestamp was created.
[LIMIT <snapshot_count>]Sets the maximum number of snapshots to be purged. Databend will select and purge the oldest snapshots.
Example
SET retention_period = 0;
-- Create a table and insert data using three INSERT statements
CREATE TABLE t(x int);
INSERT INTO t VALUES(1);
INSERT INTO t VALUES(2);
INSERT INTO t VALUES(3);
SELECT * FROM t;
x|
-+
1|
2|
3|
-- Show the created snapshots with their timestamps
SELECT snapshot_id, segment_count, block_count, timestamp
FROM fuse_snapshot('default', 't');
snapshot_id |segment_count|block_count|timestamp |
--------------------------------+-------------+-----------+---------------------+
edc9477b62c24f299c05a4d189030772| 3| 3|2022-12-26 19:33:49.0|
256f1fe2e3974ee595474b2a8cad7a39| 2| 2|2022-12-26 19:33:42.0|
1e060f7d145747578963b5a7e3b14742| 1| 1|2022-12-26 19:32:57.0|
-- Purge the historical data generated before the new snapshot was created.
OPTIMIZE TABLE t PURGE BEFORE (SNAPSHOT => '9828b23f74664ff3806f44bbc1925ea5');
SELECT snapshot_id, segment_count, block_count, timestamp
FROM fuse_snapshot('default', 't');
snapshot_id |segment_count|block_count|timestamp |
--------------------------------+-------------+-----------+---------------------+
9828b23f74664ff3806f44bbc1925ea5| 1| 1|2022-12-26 19:39:27.0|
SELECT * FROM t;
x|
-+
1|
2|
3|